

Natural language processing (NLP) is a field in a state of flux. New applications of neural network-based methods combined with huge datasets are quickly outstripping decades of incremental progress based on hand-crafting rules and features. And with the role that Python has played in the rise of data science in the last 5 years, the tooling available for processing text data with Python is changing just as rapidly. Practically speaking, this progress is exciting, but it means that choosing the right toolkit can be challenging for non-experts, and the community needs to do a better job demystifying the tradeoffs between different packages.
What does it mean to do NLP?
Roughly speaking, there are two distinct types of tasks in NLP. The first goal is typically to take raw text and extract some structured data from it. Sometimes, this is as simple as tabulating n-gram counts or co-occurrence statistics. But often, this means parsing the text to tag parts of speech, build a dependency tree, and identify named entities.
A collection of n-gram counts or an annotated sentence isn’t very useful on its own, though. Once you preprocess your raw text, the next step is doing something interesting with the structured data you’ve pulled out. In 2017, that often means applying a clustering or classification algorithm to determine the intent of an input question or decide whether a social media post contained a positive or negative reaction.
In this post, I’ll focus on the two giants when it comes to parsing English text with Python – NLTK and spaCy – and how each fares on part-of-speech tagging (though these lessons generalize to other text parsing tasks). Both tools are excellent in their own right, but their ideal use cases are quite different, and understanding the motivation and philosophy behind each tool will help you choose the right one for your project. In a follow-up post, I’ll dig into the second task of doing interesting things with the data you’ve extracted.
NLTK
NLTK (Natural Language Toolkit) is the elephant in the room. Dating all the way back to 2001, NLTK was, for a long time, the place to go for NLP in Python. Adding to its popularity was an online book that doubles as extended documentation for the package and an introductory textbook that could be used in a 1-semester course on NLP.
The history and philosophy of NLTK is best described by the authors themselves:
The Natural Language Toolkit, or NLTK, was developed to give a broad range of students access to the core knowledge and skills of NLP (Loper and Bird, 2002). In particular, NLTK makes it feasible to run a course that covers a substantial amount of theory and practice with an audience consisting of both linguists and computer scientists.
These deep roots in academia make NLTK a great choice for learning and teaching concepts in NLP. In particular, NLTK provides easy access to classic benchmark corpora like the Brown dataset and the Penn Treebank and functionality for implementing “classical” NLP tasks like defining context-free grammars.
But the design decisions that make NLTK a good tool for the classroom also make it a difficult tool to use in production applications. Most notably, NLTK is written in pure Python, which means that multi-threading performance is limited by the GIL and execution speed can be prohibitively slow for internet-scale corpora.
In addition, let’s face it – the NLTK API and documentation leave much to be desired. The `nltk.tag` module alone contains an off-the-shelf tagger in addition to 13 separate submodules that either implement or wrap other taggers. The documentation for this module runs about 9,000 words, but gives very little information about the tradeoffs between the different available models. In other words, a huge portion of the codebase is only usable if (a) you already have a deep understanding of the provided models and (b) are willing to read the source code to determine how exactly to use each one.
The bottom line with NLTK is that if you’re teaching a class in NLP with Python, NLTK offers easy access to classic corpora and some nice capabilities for demonstrating theoretical concepts. But if you’re a developer building an NLP product for the modern web, NLTK is almost certainly too slow for you, and if you’re a beginner looking to do a small NLP side project, NLTK is probably too complicated for you.
spaCy
In the last couple years, a new player has emerged in the Python text parsing landscape. Created and actively developed by Matthew Honnibal, much of spaCy’s design is (in part) a direct response to the approach that NLTK takes:
There’s a real philosophical difference between spaCy and NLTK. spaCy is written to help you get things done. It’s minimal and opinionated. We want to provide you with exactly one way to do it — the right way. In contrast, NLTK was created to support education.
In practice, this means two things for a pragmatic developer: spaCy is fast, and spaCy is simple.
First, spaCy is designed to be fast – nearly the entire package is written in Cython rather than pure Python, giving it significantly better single-threaded performance. A quick performance comparison shows how dramatic the effect is:
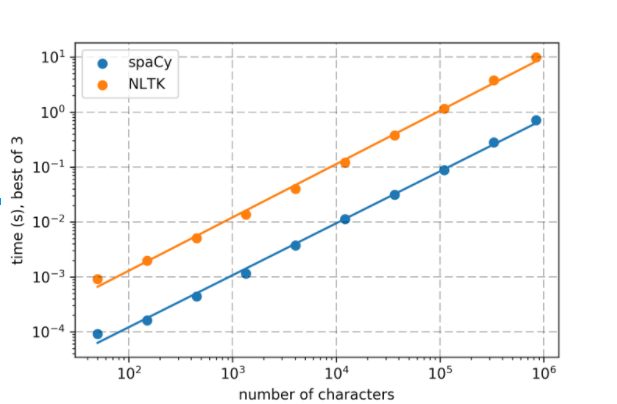
Applying a tokenizer and tagger to subsets of Dracula. Reported times are the minimum of three runs on a mid-2015 15″ MacBook Pro. The slopes of both regression lines are 0.99, with R2 > 0.99. Code is available here.
More detailed performance tests are available, but the trend is consistent – spaCy is typically at least an order of magnitude faster than NLTK on the same task, with similar or higher accuracy. And when dealing with many documents at once, you can take full advantage of multi-core machines by releasing the GIL for true shared-memory parallelism.
spaCy’s simple API is another big selling point – instead of including 14 taggers, spaCy has one, and as the state of the art improves, the spaCy developers promise to replace this model with an improved one. From a practical perspective, this makes getting up and running with spaCy much faster than NLTK – just import the provided model with the confidence that it’s the one you probably want.
Finally, spaCy includes a number of handy extra features, like built-in word vectors and “non-destructive” parsing that makes it easy to map annotated tokens back to their position in the original input. None of these is itself a killer feature, but they go a long way toward making spaCy feel like a “batteries included” approach to doing NLP.
In other words, spaCy requires less effort on the part of both the user and the user’s computer to accomplish the same tasks as NLTK, making it the right choice for the majority of developers and data scientists looking to apply NLP.
Other libraries
The NLP ecosystem for Python is quite a bit wider than just NLTK vs spaCy. When it comes to parsing English text, two others worth mentioning are Pattern and TextBlob.
Pattern is a collection of tools loosely focused on web mining. Related to NLP, Pattern offers a simple rules-based tokenizer and tagger, along with convenience functions for tasks like spell checking, pluralization/lemmatization, and n-gram extraction. Unfortunately, Python 3 isn’t currently supported, which is a shame given the clear superiority of Python 3 over Python 2 for text processing.
TextBlob is a “best of the best” library that takes methods from NLTK and Pattern. It largely avoids the scope creep that some other projects suffer from (e.g. there are two taggers available) and provides a dead simple API. But, like NLTK, TextBlob is 100% pure Python, meaning that the same performance critiques apply.
Overall, NLTK is a venerable education tool that’s starting to show its age, despite some recent API changes and a few other packages that wrap some of its functionality. For any research or product development project, spaCy’s emphasis on performance and ease-of-use make it the clear choice for Python users, especially when dealing with large corpora.